
Decoding AI Benchmarks: The 7 Essential LLM Benchmarks You Need to Understand
Understand the essential 7 Key LLM Benchmarks like SWE Bench, Terminal Bench, TAU Bench, GPQA etc.. that are used to evaluate the LLMs (Large Language Models)

Whenever a new AI model is released, companies tout how it outperforms others on various benchmarks. These benchmarks, often referred to by acronyms like MMLU or SWE Bench, GPQA, can seem intimidating and technical. But what exactly are they measuring?
In this article, I'll demystify AI benchmarks - explaining what they are, which ones matter most, and why they're important for evaluating large language models (LLMs).
What are LLM benchmarks?
LLM benchmarks are standardized frameworks for assessing the performance of large language models (LLMs). These benchmarks consist of sample data, a set of questions or tasks to test LLMs on specific skills, metrics for evaluating performance and a scoring mechanism.
Think of benchmarks as standardized exams for AI models. Just as students take tests to demonstrate their knowledge in different subjects, LLMs undergo various assessments to showcase their capabilities across different skills. Each benchmark evaluates specific aspects of an AI's performance.
This comparison extends further:
just as we might hire a math whiz for analytical work or a creative writer for content creation, benchmarks help us identify which AI models excel at specific tasks. Some models might perform exceptionally well at reasoning tasks but struggle with coding challenges, while others might excel at factual knowledge but falter on ethical questions.
Below, I'll walk through the most significant benchmarks used to evaluate today's leading LLMs, explaining what each one measures and why it matters for real-world applications.
We will try to understand by taking the benchmarks defined in the recent Claude 4 release - https://www.thetoolnerd.com/p/claude-4-is-here-and-its-redefining
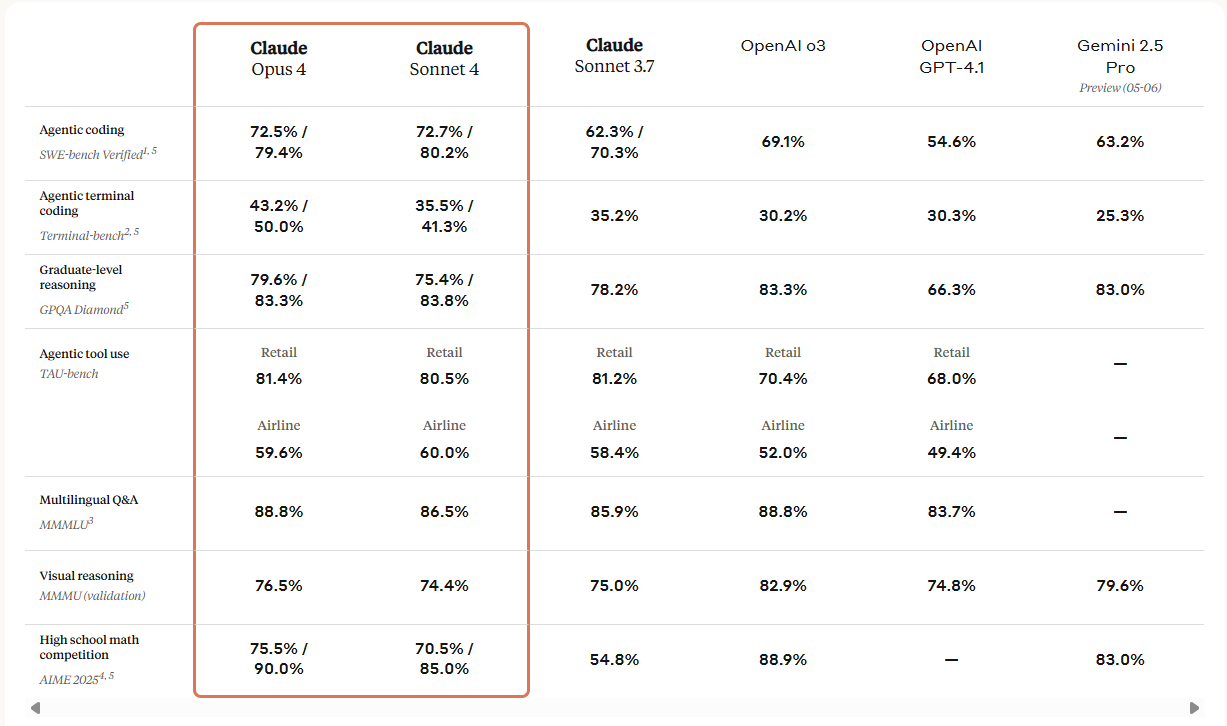
No time to read
Check out this summary table:
Let’s start one by one.
1. Agentic Coding - SWE-bench Verified
For all the developers and coders out there, this is one of the most important benchmarks that you need to know.
Purpose
Evaluates AI agents' ability to resolve real-world software engineering issues by requiring models to understand codebases, fix bugs, and implement features similar to how professional developers work.
Technical Details
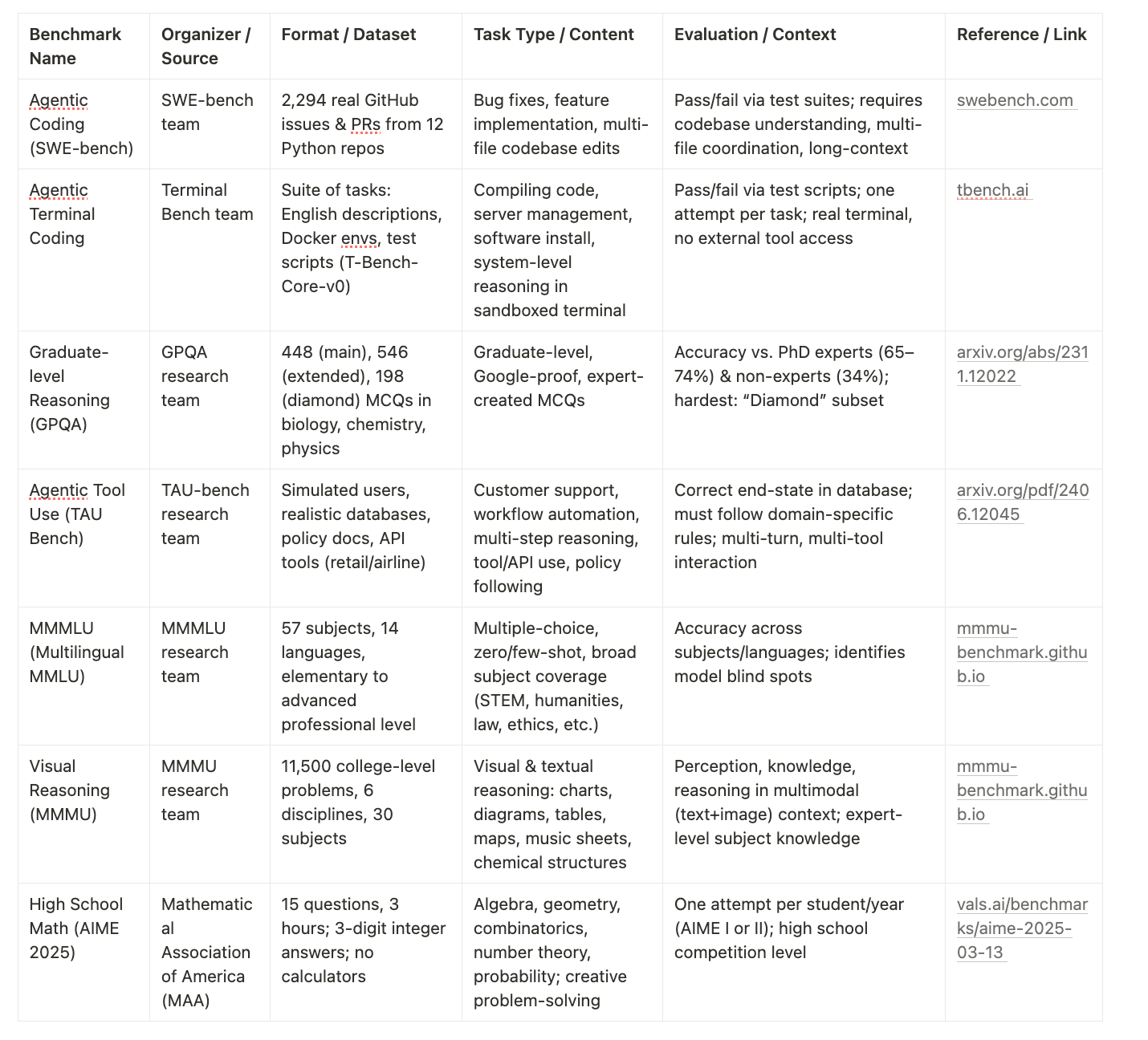
An evaluation framework consisting of 2,294 software engineering problems drawn from real GitHub issues and corresponding pull requests across 12 popular Python repositories.
Tasks require models to:
Edit codebases based on issue descriptions
Coordinate changes across multiple functions, classes, and files
Interact with execution environments
Process extremely long contexts
Perform complex reasoning beyond traditional code generation
Solutions are tested by running relevant test suites to confirm bugs are fixed while preserving existing functionality.
When to Use This Benchmark
Use SWE-bench if you care about how well an AI can handle real-world software engineering tasks—like fixing bugs, editing codebases, or implementing new features.
If you’re a developer, engineering manager, or evaluating LLMs for code automation, this is the go-to benchmark for practical coding ability in complex, multi-file projects.
Reference
Leaderboard: https://www.swebench.com/
Research Paper: https://openreview.net/pdf?id=VTF8yNQM66
2. Agentic Terminal Coding
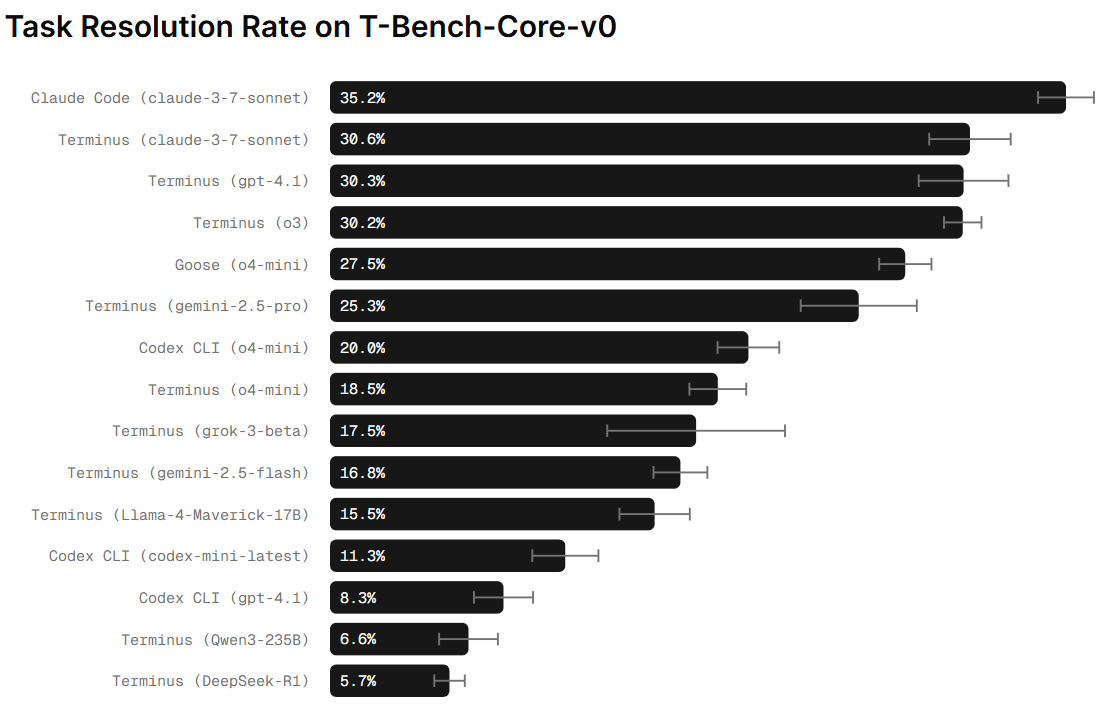
We all have heard about Claude Code and we know that it excels at terminal-based interactions. (if you haven’t heard about it , check checkout this post -https://www.thetoolnerd.com/p/i-tested-claude-code-for-a-week ). To measure its effectiveness in terminal environments, we evaluate it using Terminal Bench - a standardized performance testing framework.
This benchmark was recently developed and released in May 2025
Purpose
Tests AI agents in real terminal environments, assessing their ability to autonomously complete complex tasks like compiling code, managing servers, or installing software.
It measures practical, end-to-end system-level reasoning and tool use in a command-line setting.
Technical Details
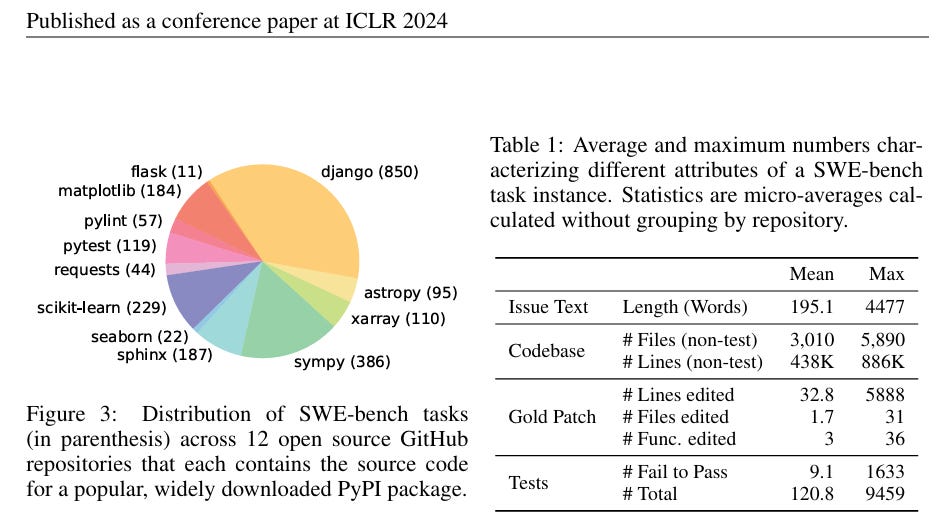
The benchmark provides a suite of tasks with English descriptions, test scripts, and reference solutions. The agent interacts with a sandboxed terminal, and success is measured by passing the test scripts.
Each agent is given exactly one attempt to resolve each task in the T-Bench-Core-v0 dataset.
Terminal-Bench consists of two parts: a dataset of tasks and an execution harness.
Dataset of tasks
Each task in Terminal-Bench includes
a description in English
a docker environment
a test script to verify if the agent completed the task successfully
a reference ("oracle") solution that solves the task
Execution harness
The execution harness connects a language model to a sandboxed terminal environment, sets up the task environments, and evaluates the agent's ability to complete the tasks.
Simply put it’s like the examination hall with limited access to external tools or books. The LLM has to solve the problem only with the knowledge it has in the test environment
When to Use This Benchmark:
Look at Terminal Bench if your use case involves automating command-line tasks, DevOps, server management, or any workflow where the LLM needs to operate in a real terminal environment.
It’s especially relevant for infrastructure engineers, sysadmins, or anyone wanting to see if an AI can actually “do” things in a shell, not just write code.
Reference
Terminal bench Leaderboard : https://www.tbench.ai/leaderboard
Website: https://www.tbench.ai/, https://www.tbench.ai/news/announcement
3. Graduate-level Reasoning - GPQA (Graduate-level Google-Proof Q&A)
GPQA stands for Graduate-level Google-Proof Q&A, and yes, it’s sounds complex. It's basically graduate level Google-proof question and answer. Now, what do you mean by Google-proof here? Basically, even if these set of questions are given to a normal non-expert individual, it is difficult for the individual to Google it out and write an answer. And this test is basically a test for AI models to actually answer the questions without searching on Google easily.
Purpose
GPQA (Graduate-level Google-Proof Q&A) is designed as a rigorous benchmark to assess the advanced reasoning capabilities of large language models (LLMs), particularly in scientific domains.
GPQA enables direct comparison between AI models and human experts, with documented accuracy rates for each group.
This makes it a valuable “litmus test” for advances in LLM capabilities, showing how close (or far) models are from true expert reasoning.
Tests true reasoning rather than simple fact retrieval
Technical Details
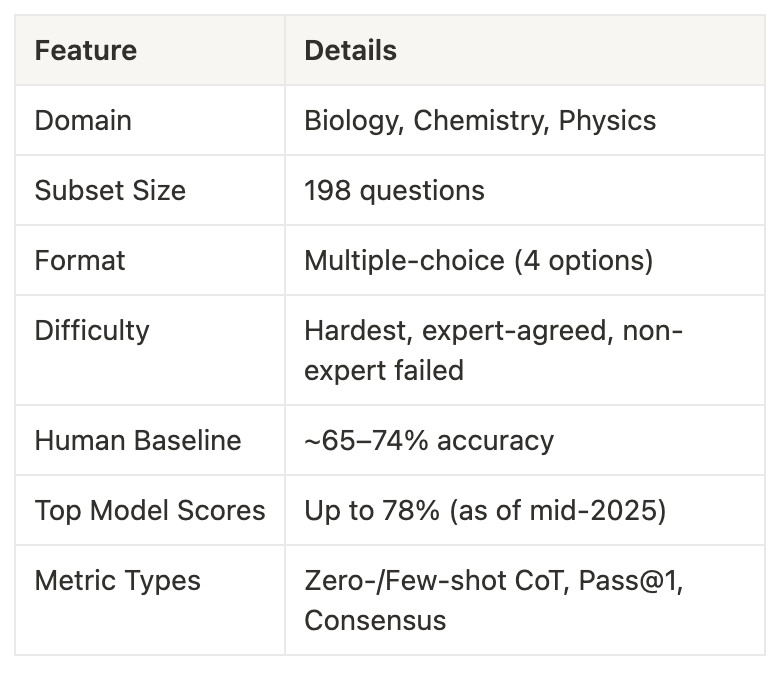
GPQA is a challenging benchmark with 448 multiple-choice questions in biology, physics, and chemistry, created by domain experts.
The questions are extremely difficult - PhD experts only achieve 65-74% accuracy, while non-experts score just 34% despite having unlimited web access for 30 mins (hence "Google-proof").
The benchmark has three versions:
Extended (546 questions)
Main (448 questions)
Diamond (198 questions)
GPQA Diamond contains only questions that experts answered correctly but non-experts failed, making it one of the toughest benchmarks for testing AI reasoning in biology, chemistry, and physics.
Structure and Content
Format: Multiple-choice questions with four options
Difficulty: Graduate-level, challenging even for PhD-level non-specialists
Example (paraphrased synthesis from official sources):
“A reaction of a hydrocarbon compound is performed under certain conditions. The NMR spectrum of the product shows a peak shifted downfield compared to the reactant. What type of element is most likely to have been added as a catalyst?”
(This type of question requires chemical understanding, knowledge of spectroscopy, and real-world context.)
You can check out the whole process that is carried out, to understand how complex and tough these questions are.

Summary Table
When to Use This Benchmark
GPQA is crucial if you need an LLM to demonstrate deep, expert-level reasoning in scientific domains (biology, chemistry, physics). If your application involves research, scientific writing, or advanced technical support, this benchmark shows whether the model can reason like a PhD, not just regurgitate facts.
References
Paper: https://arxiv.org/abs/2311.12022
GPQA Diamond is a gold standard for evaluating the frontier of scientific reasoning in AI, with ongoing updates as models improve and new evaluation methods are introduced
4. Agentic Tool Use - TAU Bench
TAU - bench, looks like an interesting acronym, right? It's simply, Tool-Agent-User Benchmark. TAU-bench (𝜏-bench) is a specialized benchmark developed to rigorously evaluate the real-world capabilities of AI agents in dynamic, interactive settings.
Purpose
TAU-bench is a benchmark designed to test how well an AI agent can:
Talk to users in a realistic conversation
Use tools (APIs) to get things done (like checking a database, external tools)
Follow rules or policies (like store or airline policies)
It’s meant to measure how well AI agents can handle real-world tasks that involve talking, reasoning, and taking action—not just answering questions.
Example: Consider this example: A user asks an agent to reschedule a flight. The agent must determine which specific tools to use—whether to access user details, booking information, cancellation services, or flight modification tools. Simultaneously, the agent needs to understand relevant policies: Is the request within 24 hours of departure (when cancellations may be restricted)? Is it a basic economy ticket (which typically cannot be modified)? Should the agent suggest an upgrade or explain additional charges?
TAU-bench excels at evaluating how well AI systems navigate these complex interactions between user requests, available tools, and domain-specific policies. This makes it particularly valuable for assessing an LLM's potential effectiveness in handling sophisticated customer support scenarios where multiple factors must be balanced simultaneously.
Technical Details
TAU-bench uses a simple framework with realistic databases, APIs, and policy documents, plus instructions for various user scenarios. It focuses on customer service in two domains: retail and airline.
The benchmark creates realistic simulated users using other AI models.
There are tasks that are defined to be executed
Example:
1. Each task includes:
A goal (e.g. “cancel a customer’s order”)
Simulated users who talk like real people (generated by another AI)
A hidden database that stores information (e.g., customer orders)
A set of rules or policies the AI must follow (e.g., “Orders can’t be canceled after 14 days”)
2. The AI agent can:
Talk to the user to ask questions or confirm things
Use tools or APIs to view or update the database
Read documents (rules or policies) to make the right decisions

(a) In τ-bench, an agent interacts with database API tools and an LM-simulated user to complete tasks. The benchmark tests an agent’s ability to collate and convey all required information from/to users through multiple interactions, and solve complex issues on the fly while ensuring it follows guidelines laid out in a domain-specific policy document. (b) An example trajectory in τ-airline, where an agent needs to reject the user request (change a basic economy flight) following domain policies and propose a new solution (cancel and rebook). This challenges the agent in long-context zero-shot reasoning over complex databases, rules, and user intents.
Evaluation is based on whether the agent achieves the correct end-state in the database, not just conversation quality.
When to Use This Benchmark:
Use TAU Bench if your LLM needs to interact with APIs, databases, or external tools while following complex rules or policies—think customer support bots, workflow automation, or any scenario where the AI must “do” things, not just chat.
It’s ideal for evaluating real-world, multi-step task handling and compliance.
References
Paper : https://arxiv.org/pdf/2406.12045
5. Multilingual Massive Multitask Language Understanding (MMMLU)
MMLU (Massive Multitask Language Understanding) is a famous benchmark designed to measure knowledge acquired during pretraining by evaluating models exclusively in zero-shot and few-shot settings.
MMLU’s test set into 14 languages using professional human translators and is termed as MMMLU - Multilingual Massive Multitask Language Understanding
Purpose
The purpose of MMLU (Massive Multitask Language Understanding) is to measure the knowledge acquired by language models during pretraining by evaluating their performance across a diverse set of 57 subjects, ranging from elementary to advanced professional levels.
Technical Details
The benchmark encompasses 57 subjects across STEM, the humanities, social sciences, and other disciplines.
It ranges in difficulty from an elementary level to an advanced professional level, and it tests both world knowledge and problem solving ability.
Subjects range from traditional areas, such as mathematics and history, to more specialized areas like law and ethics.
The granularity and breadth of the subjects makes the benchmark ideal for identifying a model’s blind spots.

An extract from the Paper on the kind of questions evaluated:

I found this particularly fascinating in the paper – how the accuracy level increases with more parameters. This explains why GPT-3/3.5 created such viral excitement; it was able to demonstrate significantly better performance on general world knowledge tasks.
We find that meaningful progress on our benchmark has only become possible in recent months. In particular, few-shot models up to 13 billion parameters (Brown et al., 2020) achieve random chance performance of 25% accuracy, but the 175 billion parameter GPT-3 model reaches a much higher 43.9% accuracy (see Figure 1b). On the other hand, unlike human professionals GPT-3 does not excel at any single subject. Instead, we find that performance is lopsided, with GPT-3 having almost 70% accuracy for its best subject but near-random performance for several other subjects.
When to Use This Benchmark
MMMLU is your benchmark if you want a model that’s knowledgeable across a wide range of subjects and languages. It’s especially important for global products, educational tools, or any application where broad, multilingual general knowledge and reasoning are required.
References
Leaderboard : https://mmmu-benchmark.github.io/#leaderboard
Paper : https://arxiv.org/pdf/2009.03300v3
6. Visual Reasoning - Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU)
As humans, we are good at comprehending images like charts,diagrams, tables etc… along with that text and try to make an inference out of it. But are LLMs equally good at it or not?
Can they reason about what they see and solve problems based on visuals?
So that is what MMMU ( Massive Multi-discipline Multimodal Understanding & Reasoning) is all about.
Purpose
Evaluates multimodal models on complex, college-level tasks that require both visual and textual reasoning.
Technical Details
Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts.
MMMU is designed to measure three essential skills in LMMs: perception, knowledge, and reasoning.
MMMU presents four challenges:
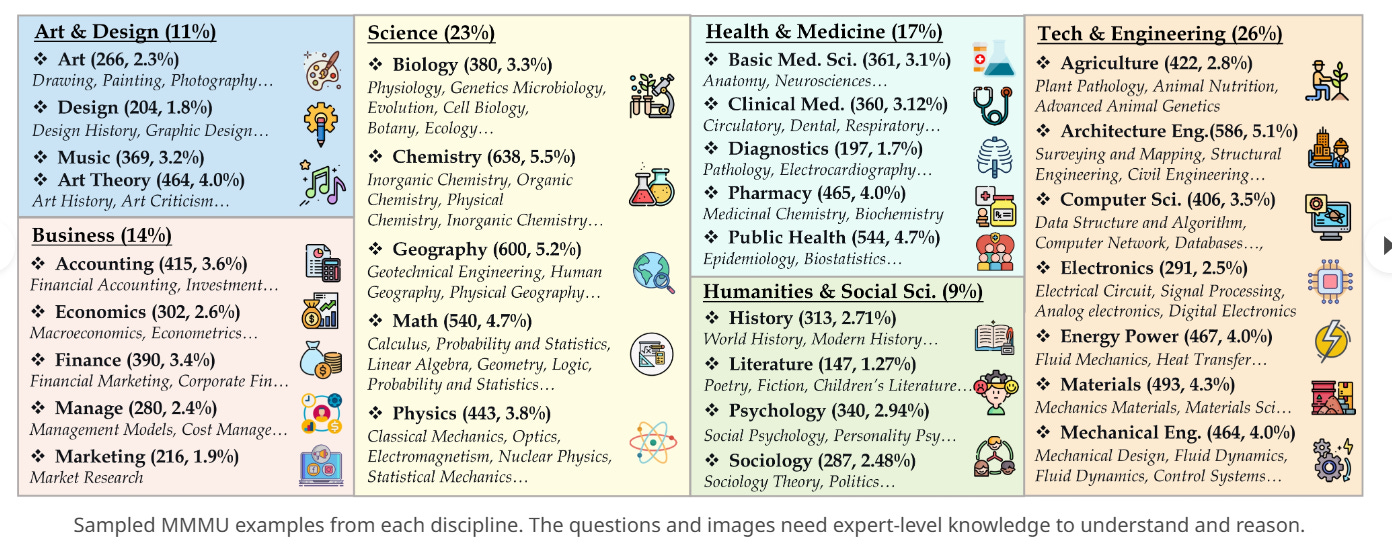
1) comprehensiveness: 11.5K college-level problems across six broad disciplines and 30 college subjects like Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering ;
2) highly heterogeneous image types - charts, diagrams, maps, tables, music sheets, and chemical structures;
3) interleaved text and images;
4) expert-level perception and reasoning rooted in deep subject knowledge.
Types of Questions part of MMMU ( Example)

Topics Covered in MMMU
When to Use This Benchmark:
Check MMMU if your use case involves interpreting images, diagrams, charts, or any multimodal content. This is key for educational tech, document analysis, or any scenario where the LLM needs to “see” and reason about both text and visuals together.
References
Paper: https://mmmu-benchmark.github.io/
7. High School Math Competition - AIME 2025
We all have given different kinds of exams in order to qualify for a seat in a top university. AIME, which is referred to as the American Invitational Mathematics Examination, is one such high school math competition.
Refers to the American Invitational Mathematics Examination, a prestigious high school math competition. It serves as a key qualifying step for the USA Mathematical Olympiad (USAMO) and the global International Mathematical Olympiad (IMO). It’s organized by Mathematical Association of America (MAA)
Purpose
To check the ability of LLM ( Large Language Model ) in solving the tough Mathematical Questions. Used as a benchmark to test mathematical reasoning and problem-solving skills of AI models at a high school competition level.
Technical Details
The AIME consists of challenging math problems that require creative problem-solving and advanced mathematical reasoning.
15 questions, 3 hours
No calculators are permitted
Algebra, Geometry, Combinatorics, Number Theory & Probability
When to Use This Benchmark
AIME is the benchmark to watch if you need strong mathematical reasoning at the high school competition level—great for math tutoring apps, STEM education, or any product where creative problem-solving in math is a must.
References
Leaderboard : https://www.vals.ai/benchmarks/aime-2025-03-13
Conclusion
So, next time you see a flashy AI announcement boasting about “topping the leaderboard” or “crushing benchmarks,” you’ll know exactly what’s under the hood. Whether you’re picking an LLM for coding, customer support, or solving a math riddle, benchmarks will help you select the right one for your use case
Of course, no single test can capture the full magic (or madness) of AI. But together, these benchmarks are the compass guiding us through the ever-evolving landscape of large language models.