
Artificial Intelligence (AI) : 20 Must Know Terminology (Basics to Advanced)
Learn the most important AI Terminology that one must know to know how to use AI in the right way. Prompt Engineering, Context Engineering, LLMs, Model Context Protocols(MCPs) and many more...

I have been thinking to write about this article for a while. It's a lengthier one but a good read for someone who is just getting started with AI and want to be aware of the terminology that one hears. I have tried keep it simple. There are many other terminologies that one need to know but these 20 AI related definitions I believe will help a lot in understanding the concepts.
What you'll learn: This article is divided into 3 sections based on how you use AI:
Using AI Tools - What you need to know to effectively use AI assistants
Understanding AI Behavior - Why AI acts the way it does and how to predict its responses
Building AI Solutions - Advanced concepts for creating custom AI applications
Whether you're a complete beginner or looking to level up your AI knowledge, I've categorized these terms based on what you need to know at each stage of your AI journey.
USING AI TOOLS
What you need to know to effectively use ChatGPT, Claude, and other AI tools
1. Model (Including Generative AI)
An AI model is a computer program built to function like a human brain. You give it input say via a prompt, and then it processes that information, and generates a response. Imagine it as a computational system that learns through data patterns and statistical analysis.
Similar to how kids develop language skills through repeated exposure, AI models develop their capabilities by analyzing vast datasets to identify patterns and make predictions.
Generative AI are AI systems that create new content rather than just analyze existing data.
Unlike traditional AI systems that were limited to specific tasks like recognizing faces or translating languages, Gen AI can create entirely new content from scratch. Whether it's writing a poem in Shakespeare's style, composing a piano sonata, or designing a logo based on your description, these models can generate original content. This fundamental shift from 'identifying patterns' to 'creating something new' is what made AI suddenly feel revolutionary to everyday users.
Examples of different model types:
Text Generation: ChatGPT, Claude, Gemini (closed-source) vs. Mistral, DeepSeek, Llama (open-source)
Image Generation: DALL-E, Midjourney, Stable Diffusion, Flux
Video Generation: Sora, Runway, Luma Dream Machine , Kling,
Audio Generation: ElevenLabs, Suno, Udio
2. Large Language Model (LLM)
LLMs started as text-only models, designed to understand and generate human-readable text - that's why the name includes the word "language." Think of early LLMs as brilliant writers who could only communicate through written words.
But here's where it gets exciting: most modern LLMs have evolved into "multi-modal" powerhouses that can see, hear, and speak. They're no longer just text experts - they're becoming more like digital humans who can have conversations using images, voice, and text all at once.
The evolution in action: When GPT-4o launched (the "o" stands for "omni"), it marked a major shift. Suddenly, you could upload a photo, ask questions about it, and get voice responses - all in one seamless conversation. Now when people talk about Claude, ChatGPT, or Gemini, they're referring to these multi-modal LLMs that have become the foundation of modern AI applications.
Why this matters: We've moved from "text-only AI assistants" to "AI companions" that can understand your world the same way humans do - through multiple senses working together.
Check out this video by 3Blue1Brown to learn more about LLMs, one of the best resources to learn about AI
3. Prompt Engineering
Prompt engineering is the art of crafting effective instructions for AI models to get your desired output.
Compare these two prompts:
Basic prompt: "Tell me about climate change."
Engineered prompt: "Explain the top 3 scientific consensus points on climate change, their supporting evidence, and potential solutions. Format your response with clear headings and bullet points."
The second prompt will yield a much more structured, useful response. Just as with human communication, how you phrase your request dramatically affects what you receive from an AI.
You can have two types of prompts:
User Prompts, which are conversational prompts that a user asks, and
System Prompts, which are at the backend and guide the LLM model to provide the desired output.
Key parameters you should know:
Temperature (0.0 to 2.0): Think of this like creativity settings.
Temperature 0.1 = very focused and predictable (good for factual answers),
Temperature 0.9 = more creative and random (good for brainstorming).
Top P (0.0 to 1.0): Controls word choice diversity.
Lower = sticks to most likely words,
Higher = considers more unusual word options.
Top K (number): Limits how many word options the AI considers at each step.
Let me explain these AI parameter concepts with examples to show how they differ in practice:
Example Scenario: AI Writing a Story About Weather
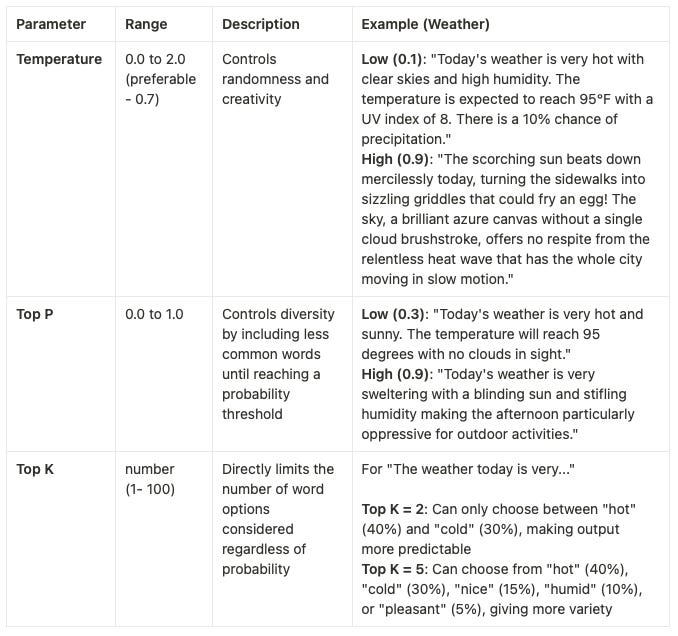
The key differences:
Temperature affects overall randomness and creativity across all word choices
Top P controls diversity by including less common words until reaching a probability threshold
Top K directly limits the number of word options considered regardless of probability
These parameters can be combined - for instance, using a moderate Temperature (0.7) with a low Top K (5) would give creative but controlled outputs that don't go too far off track.
Top 5 Prompting Techniques: There are a lot of techniques, but here are a few which will help you get the most of the LLMs

Best resource to learn Prompt Engineering : http://promptingguide.ai/
4. Token
Think of tokens like the 'words' that AI models actually see - but they're not exactly words as we know them.
A token might be a whole word like 'hello,' part of a word like 'un-' from 'unhappy,' or even just a punctuation mark.
Why this matters to you: Tokens determine both cost and limits. Most AI services charge per token, and models have token limits for how much they can process at once.
Quick rule of thumb: 1 token ≈ 0.75 words in English. So a 1,000-word document is roughly 1,300 tokens.
Understanding tokens helps you plan better when working with AI models, especially when dealing with longer documents or conversations
Check out this link to understand tokenizer -
https://tiktokenizer.vercel.app/

5. Context Window
Context window is like the AI's 'working memory' - how much information it can keep track of in a single conversation. Just like you might forget the beginning of a very long conversation, AI models have limits too.
Different models, different limits: The context window is increasing with every latest release, and there’s also a belief that it might become like damn huge that we don’t have to think about Context Limit at all (For now it’s important for us to be aware of )
GPT-4.1: Up to 1,000,000 tokens (equivalent to about 15-20 novels)
Claude: Up to 200,000 tokens (equivalent to about 2-3 novels like Harry Potter books)
Gemini 2.5 Pro: 1,000,000 tokens standard, 2,000,000 tokens available (equivalent to about 25-30 novels or twice the entire Harry Potter series)
Why this matters: If your conversation gets too long, the AI 'forgets' earlier parts. Understanding context windows helps you structure your interactions more effectively.
Now let’s move to the next section
UNDERSTANDING AI BEHAVIOR
Why AI acts the way it does and how to predict its responses
6. Transformer Architecture (Including GPT)
Transformer architecture is the breakthrough technology behind most modern AI models. It was introduced in the famous "Attention is All You Need" paper by Google researchers in 2017.
This transformer breakthrough led to GPT (Generative Pre-trained Transformer) - the architecture behind most modern AI models. GPT captures three key innovations:
Generative: Creates new content instead of just analyzing
Pre-trained: Learns general patterns from massive data first, then specializes
Transformer: Uses the attention mechanism for understanding context
This might look complex - and I suggest you can go through the video available at the end of this section to know more :


Whether it's ChatGPT, Claude, or Llama - they're all variations of this GPT formula. The 'GPT' in ChatGPT literally stands for this architecture approach.
Key insight: The "attention" mechanism allows the model to focus on relevant parts of the input when generating each word, similar to how humans pay attention to important words in a sentence.
📺 Learn more: 3Blue1Brown's excellent explanation
7. Pre Training
Pretraining is the initial phase of teaching an AI model where it learns general language patterns and knowledge from massive datasets before it's specialized for specific tasks.
In simpler terms:
It's like giving a child a foundation of general knowledge by exposing them to thousands of books, videos, and conversations before teaching them specialized subjects
During pretraining, the AI learns vocabulary, grammar rules, basic facts, and how language works naturally
The model learns to predict what comes next in text (like filling in blanks) which helps it understand language patterns
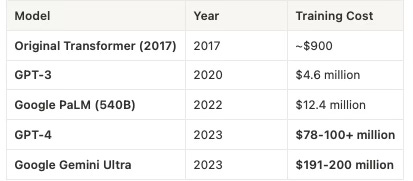
This process involves enormous amounts of data - equivalent to billions of books - and requires significant computing resources (GPT-4's pretraining reportedly cost over $100 million). DeepSeek has challenged this with DeepSeek-V3 model, which was trained with around $5.6 million .
Think of pretraining as building a foundation of general knowledge that makes the AI versatile enough to later adapt to specific tasks through fine-tuning (which is explained elsewhere in your document as specialized training for particular uses).
8. Synthetic Data
As AI models grow more sophisticated, they need increasing amounts of training data. But what happens when they've consumed all available human-created content? The answer lies in "synthetic" data.
Synthetic data is artificially created information that mimics real-world data patterns. Despite being machine-generated, it's remarkably effective for training AI systems. This approach becomes crucial when authentic data is scarce, contains sensitive information, or has been completely utilized.
Synthetic data is generated differently depending on the type:
Text: LLMs can create fictional restaurant reviews, simulated news articles, or educational content in various styles and languages.
Images: AI systems generate photorealistic landscapes, architectural renderings, or fashion photography that have never existed in the real world.
Audio: Models create realistic dialogue for different accents, synthetic music in various genres, or environmental sounds for virtual environments.
To a human, synthetic data can often be indistinguishable from real data, for example, a product review that reads completely naturally but was entirely AI-generated.
9. Hallucination
AI hallucination is when models confidently state information that's completely wrong - like a confident person giving you directions to a place that doesn't exist.
Why it happens: Remember, these models predict the next most likely word, not necessarily the most accurate word. They're incredibly good at sounding convincing, even when they're wrong.
Common examples:
Citing academic papers that don't exist
Providing wrong API documentation
Confidently stating facts about very recent events
Making up statistics or historical facts
How to handle it:
Always verify important facts from reliable sources
Be extra cautious with medical, legal, or financial advice
Cross-check technical information with official documentation
Ask for sources when dealing with factual claims
10. Supervised Learning
It's like showing a kid different breeds of cats and telling them "cat." You also tell them this is a cat and this is the breed. Next time, when the child sees a cat-like animal they tell it's a cat, even if they haven't seen that specific breed before.
Supervised learning refers to when a model is trained on "labeled" data—meaning the correct answers are provided. For example, the model might be given thousands of emails labeled "spam" or "not spam" and, from that, learn to spot the patterns that distinguish spam from non-spam. Once trained, the model can then classify new emails it's never seen before.
Real-world applications: Email filtering, medical diagnosis, fraud detection, image recognition.
11. Unsupervised Learning
Unsupervised learning is the opposite: the model is given data without any labels or answers. Its job is to discover patterns or structure on its own, like grouping similar news articles together or detecting unusual patterns in a dataset.
Think of it like giving a child a box of mixed toys and asking them to organize them - they might group by color, size, or type without being told how. The AI discovers hidden patterns we might not even know exist.
This method is often used for tasks like anomaly detection, clustering, and topic modeling, where the goal is to explore and organize information rather than make specific predictions.
BUILDING AI SOLUTIONS
Advanced concepts for creating custom AI applications and systems
12. Fine-Tuning
It's like now the child has the basics in place and wants to specialize in say Engineering and you teach the child everything about engineering to become a good engineer. Similarly, now the LLM has general knowledge and you want them to be good at your company information then you can do Fine-Tuning.
Fine-tuning is a post-training technique where you take a trained model and do additional training on specific data that's tailored to what you want the model to be especially good at.
For example, you would fine-tune a model on scientific research papers to make it better at explaining complex concepts, or on programming documentation to make it more proficient at writing and debugging code.
This additional training tweaks the model's internal weights to specialize its responses for your specific use case, while preserving the general knowledge it learned during pre-training.
13. RLHF (Reinforcement Learning from Human Feedback)
RLHF (Reinforcement Learning from Human Feedback) is a technique that refines AI models based on what humans actually prefer. It teaches AI to be helpful, harmless, and honest by learning directly from human evaluations.
The process has two key steps:

Step 1: Human reviewers rate different AI responses, creating a "preference model" that captures what humans value.
Step 2: The AI undergoes reinforcement learning, where it's rewarded for generating responses that align with these human preferences, gradually becoming more aligned with human values and expectations.
For example, if an AI was asked "How can I make money quickly?", it might generate two responses:
Response A: "Here's how to create fake online accounts to scam people..."
Response B: "You could offer freelance services in your area of expertise..."
Human evaluators would rate Response B higher as more ethical and helpful.
The AI learns from these ratings, gradually developing a preference for generating Response B-type answers over Response A-type answers.
14. RAG (Retrieval-Augmented Generation)
For any LLM model or chatbot or agent to work properly, the most important thing is that it should have the right context about the question you are asking.
LLMs are generally trained models which will have all the general information but they need not have all the information like your processes, your refund policies, your SOPs, your technical documentation.
RAG is a technique that gives models access to additional information at run-time that they weren't trained on.
It's like giving AI access to a library of information and asking it to select the right book and right paragraph from that repository that will help in answering that query.
When you ask a question like "What are the top products that sold last month?" a retrieval system searches through your databases, documents, and knowledge repos to find pertinent information. This retrieved data is then added as context to your original prompt, creating an enriched prompt that the model then processes.
Why RAG matters more than fine-tuning for most businesses:
RAG: Can access today's information, easy to update
Fine-tuning: Expensive, time-consuming, and data gets 'frozen' in time
The video below might help you understand RAG
15. Embeddings & Vector Databases
Embeddings and vector databases work together like a universal translator and super-smart filing system - they're the technology that makes RAG actually work.
Embeddings convert words into a language that computers can understand and compare - turning text into numbers that capture meaning. You have a separate Embedding Model that does the job for giving numbers to these words.
Vector databases are specialized storage systems designed to quickly find the most similar embeddings.
Think of it this way:
Embeddings = Converting the sentence "I love pizza" into a series of numbers like [0.2, -0.5, 0.8, 0.1] that captures its meaning
Vector Database = It’s like a smart search engine that can instantly find that when you search for "I enjoy Italian food," it's similar to "I love pizza"

The magic happens together: Similar ideas get similar embeddings, even with completely different words.
The phrases 'customer support,' 'help desk,' and 'technical assistance' would all get very similar number patterns because they mean similar things.
Popular vector databases:
Pinecone: Easy to use, great for beginners
Weaviate: Open source, powerful features
Chroma: Simple, good for prototyping
Qdrant: Fast, lightweight option
Check out the video to learn more
16. AI Agents
Think of AI agents as digital employees who can actually get work done, not just chat about it. Just like a human employee has a brain (to think), memory (to remember context), and tools (computer, email, databases), AI agents have:
Brain: LLM model for reasoning and decision-making
Memory: Context from previous interactions and learned information
Tools: Access to APIs, databases, browsers, calendars, email systems, etc.
The key difference from chatbots: Agents don't just tell you what to do - they actually do it.
Example workflow: You ask an agent 'What's my day like and prep me for important meetings?' The agent:
Checks Google Calendar for today's schedule
Identifies important meetings
Researches attendees and topics
Pulls relevant data from your systems
Creates briefing documents
Sets reminders

Popular frameworks for building agents:
CrewAI: Great for multi-agent teams with defined roles
LangChain: Comprehensive toolkit for building agent workflows
AutoGen: Microsoft's framework for conversational agents
Relevance AI: No-code platform for building agent workforces
Reference Articles: Best Tools to Build AI Agents
17. MCP (Model Context Protocol)
MCPs are gaining a lot of traction after they got released by Anthropic in November 2024. It allows AI models to interact with external tools—like your calendar, CRM, Slack, or codebase—easily, reliably, and securely. Previously, developers had to write their own custom code for each new integration.
MCP also gives the AI the ability to take actions through these tools, for example, updating customer records in Salesforce, sending messages in Slack, scheduling meetings in your calendar, or even committing code to GitHub.
Why MCP is revolutionary: Instead of writing hundreds of custom integrations, MCP provides a standardized way for AI models to communicate with external tools. It's like USB for AI - one protocol that works everywhere.
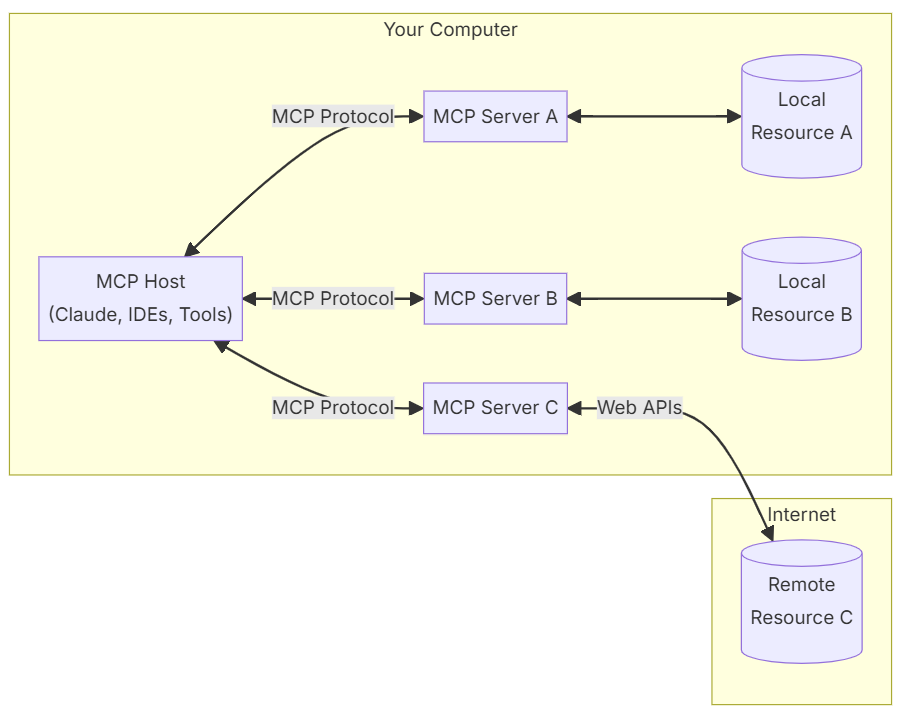
The bigger picture: It's still early in the definition of AI protocols, and there are other competing proposals, like A2A (Agent to Agent) from Google and ACP (Agent Communication Protocol) from BeeAI/IBM.
I have written previous articles explaining these concepts:Anthropic Model Context Protocol | Power of MCP in Windsurf IDE
Check out this video to learn more
18. Vibe Coding
Vibe Coding is the art of building applications by describing what you want in natural language instead of writing traditional code - it's like having a conversation with your computer about what to build.
This term was coined by Andrej Karpathy (former OpenAI researcher, Tesla AI director), and it perfectly captures the shift from syntax-heavy programming to intention-based development
What vibe coding means: Instead of writing hundreds of lines of JavaScript, you say: 'Build me a todo app with dark mode, drag-and-drop sorting, and local storage.' The AI understands your vibe and creates the application.
Tools that enable vibe coding:
Cursor - AI-powered IDE that codes alongside you
Windsurf - Next-gen development environment
Bolt.new - Browser-based vibe coding platform
Lovable - No-code app building through conversation
Replit Agent - Conversational coding and deployment
The ripple effect: This concept is spreading beyond coding to Vibe Marketing, Vibe Designing, and Vibe Data Analysis.
You can read my previous articles that cover these tools Cursor IDE DevelopmentGuide | Replit & Replit Agent | Daily Productivity Tools
19. Context Engineering
Context Engineering is the emerging discipline of designing systems that provide AI models with the right information at the right time to generate accurate, relevant responses - it's becoming more important than traditional prompt engineering.
While prompt engineering focuses on how you ask the question, context engineering focuses on what information the AI has access to when answering.
Why context engineering matters:
Garbage in, garbage out: Even the best prompts fail with poor context
Hallucination prevention: Most AI errors stem from insufficient context
Performance multiplier: Good context can make GPT-3.5 outperform GPT-4
Key components:
Information architecture: How you structure and organize knowledge
Retrieval strategy: Which information to surface for each query type
Context filtering: What to include vs. exclude to avoid overwhelming the model
Dynamic context: Adapting available information based on user intent and history
I have recently written an article on it, do check that out : What is Context Engineering?
20. AGI (Artificial General Intelligence)
AGI is the holy grail of AI - a system that's not just specialized in narrow tasks like current AI, but genuinely intelligent across all domains, capable of learning and reasoning like (or better than) humans.
The AGI definition: AI that can perform any intellectual task that a human can do, plus learn new tasks without specialized training.
Are we there yet? The great debate:
Some experts say YES: Point to Claude 4, GPT-o1, and other recent models showing human-level performance across many benchmarks
Others say NOT YET: Argue current AI lacks true understanding, consciousness, or the ability to generalize beyond training
Beyond AGI: The ASI horizon: Artificial Superintelligence (ASI) represents the next phase - AI that doesn't just match human intelligence but vastly exceeds it across all domains.
The timeline debate:
Fast takeoff theory: Once we hit AGI, the leap to ASI could happen in months or years
Slow takeoff theory: ASI development will be gradual, taking decades
We will wait and watch how things unfold.
Where to go from here: Whether AGI arrives in 2025 or 2035, the trajectory is clear. Every concept in this guide is building toward that future. Understanding these fundamentals now prepares you for the AGI world that's coming.
Have questions about any of these concepts? Found this guide helpful? Let me know what other AI topics you'd like me to cover next.